Documentation Index
Fetch the complete documentation index at: https://docs.landing.ai/llms.txt
Use this file to discover all available pages before exploring further.
May 19, 2026: New Playground Features for Parse and Section
Section Is Now Available in the Playground
You can now use in the Playground. After you parse a file, add the Section tool to your project and runs automatically on your files.In the Playground, you can:- Review the generated table of contents as a hierarchical tree, and toggle between Formatted and JSON views.
- Refine the table of contents by submitting natural-language guidelines.
- Export a ready-to-use script for the API or the library.
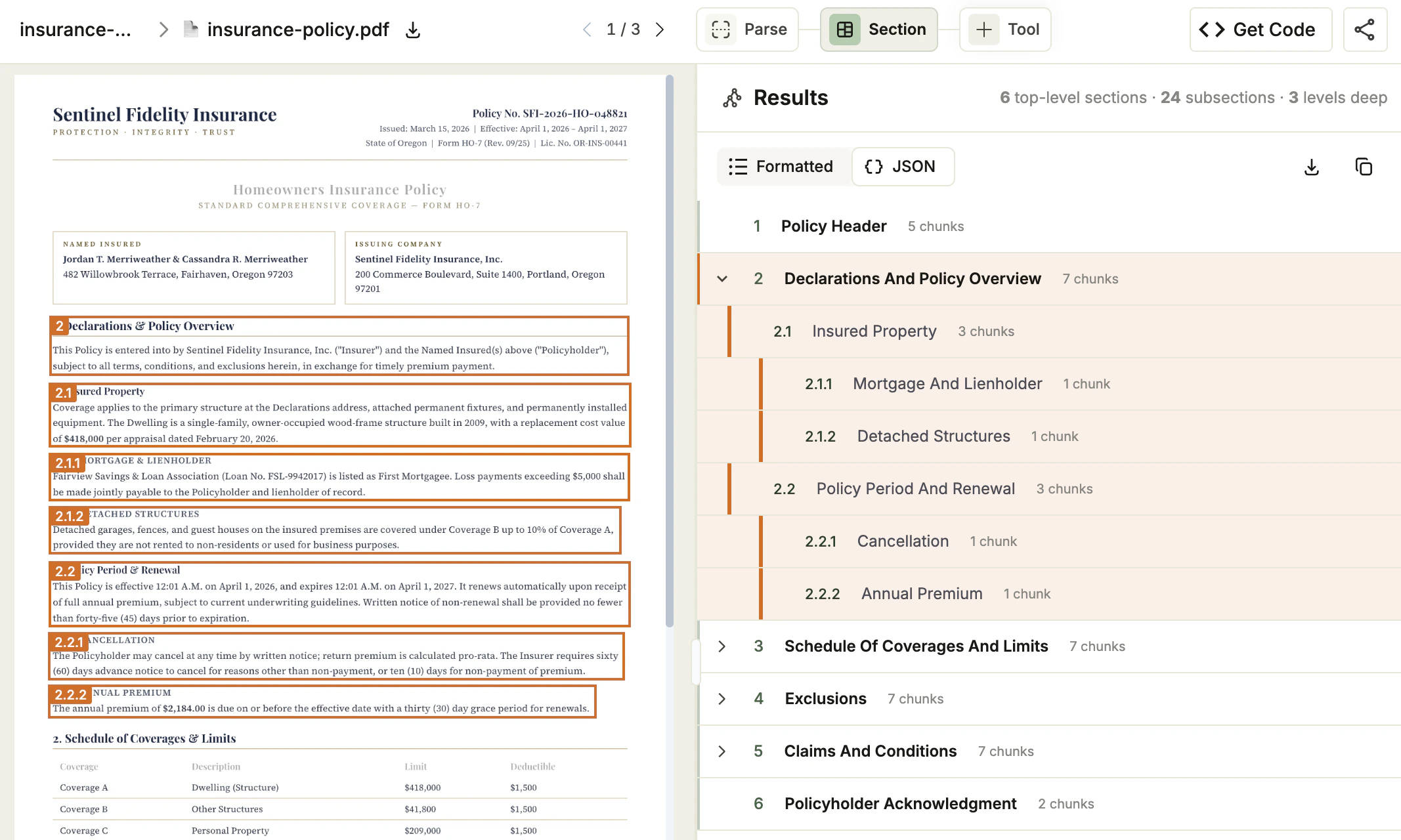
is in Preview. This feature is still in development and may not return accurate results. Do not use this feature in production environments.
New Config Drop-Down for Parse
The Parse tool in the Playground now includes a Config drop-down for selecting the parsing model and applying a custom figure prompt to your project.When you change the model or the prompt, the Playground re-parses every file in the project.For more information, see: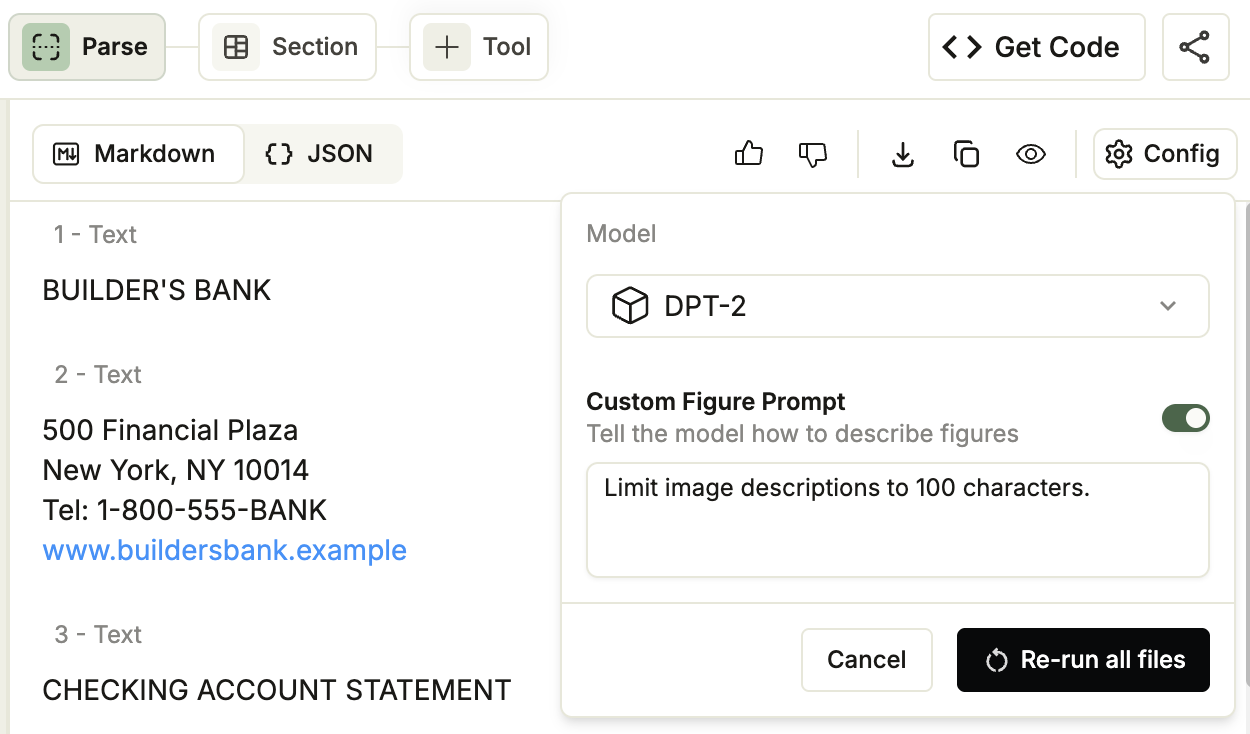
April 24, 2026: Updated Playground Design
Updated Playground Design
The Playground has a new look.The updated design makes it easier to load files and get started, and surfaces more resources directly in the left side-navigation panel, including:- APIs: Quick access to the ADE API reference
- Plan & Billing: View and manage your plan and billing information
- Events: View your processing activity
April 22, 2026: New APIs: ADE Classify and ADE Section
Two new APIs are now available in public preview:
ADE Classify
classifies each page of a document by category. You provide a document and a list of classes, and the API assigns a class to each page concurrently.Use the results to route pages to downstream systems such as Parse, Split, or Extract.Get started with .ADE Section
generates a hierarchical table of contents from a previously parsed document.It accepts the Markdown output from (which contains reference anchors) and returns a flat, reading-order list of sections with their hierarchy levels and chunk references.Get started with .A Note About Public Preview
These APIs are in Preview. These features are still in development and may not return accurate results. Do not use these features in production environments.
April 13, 2026: New Parsing Model Snapshot: dpt-2-20260410
New Parsing Model Snapshot: dpt-2-20260410
A new snapshot of is now available:dpt-2-20260410.dpt-2-20260410 builds on previous versions with these improvements:- Improved cell parsing in forms and tables: Text positioned at different locations within a cell is now captured more completely.
- Improved column alignment in complex tables: Cell data now more accurately aligns with its corresponding column headers.
How This Affects Your Results
If your code usesdpt-2-latest or dpt-2, it now points to this new snapshot and your parsing results may change.To receive the latest improvements automatically, continue using a -latest alias. To maintain consistent results over time, pin your code to a specific snapshot (for example, dpt-2-20260302). For more information, go to Why Model Versioning Matters.April 2, 2026: Extract Updates
This release includes a new extraction model version, an updated API with expanded schema support, the API for programmatic schema creation, and a new projects experience in the Playground. It also introduces credit usage for AI-powered schema building tools.
- New Extraction Model: extract-20260314
- Expanded Extraction Functionality
- Build Extract Schema API
- Projects in the Playground
- Schema Building Tools Consume Credits
New Extraction Model: extract-20260314
All extraction improvements in this release require modelextract-20260314. For a full list of what this model enables, see extract-20260314.- If you use
extract-latest: no changes needed. You already have access to the new model. - If you specify a model version in your code: update it to
extract-20260314to access these improvements.
Expanded Extraction Functionality
The API no longer has limits on schema length, number of nested levels, or other schema constraints.Cross-Page Table Reconstruction
Tables that span page breaks are now returned as a single array, with no post-processing needed.Long Document Support
The API now supports documents of 1,000 or more pages, without splitting or merging files first.Build Extract Schema API
The new API lets you programmatically create and update extraction schemas, providing the same schema-building capabilities as the Playground.Projects in the Playground
Files in the Playground are now organized into projects. Projects let you group similar documents together and create and apply extraction schemas across multiple documents at once.Schema Building Tools Consume Credits
Running AI-powered schema building tools consumes credits. This applies to:- The Refine Schema, View Suggested Fields, and Write a Schema Prompt tools in the Playground
- The API
April 2, 2026: Prepaid Credits, Auto Recharge, and Organization Updates
This release changes how subscription plans handle usage beyond the credit allocation for your billing cycle. These changes ensure that exceeding your credits does not disrupt your service.
- No more overage charges. Purchase prepaid credits in advance to cover usage beyond the credit allocation for your billing cycle.
- Auto Recharge as a buffer. Automatically purchase credits when your balance falls below a set threshold.
- Explore credits count too. If you upgraded from an Explore plan on or after April 2, 2026, your unused Explore credits are added to your buffer.
Prepaid Credits Replace Overage Charges
Overage charges for subscription plans have been eliminated. Previously, if you exceeded your allocated credits for a billing cycle, you were billed after the fact.You can now purchase “Pay-As-You-Go” credits in advance. If you exceed your allocated credits for a billing cycle, the prepaid credits are used automatically.This change goes into effect for your upcoming billing cycle. To learn more, go to OveragesAuto Recharge Now Available on Subscription Plans
Auto Recharge was previously available only on the Explore plan. It is now also available on subscription plans.Auto Recharge is enabled by default on subscription plans. When your credit balance falls below a set threshold, credits are purchased automatically. To learn more, go to Auto Recharge.Explore Credits Transfer When You Upgrade
If you upgrade from a Personal account to a subscription plan on or after April 2, 2026, your unused credits transfer to your new organization and are added to your credit pool.This pool is drawn from if you exceed your credit allocation for a billing cycle, with credits that expire soonest consumed first.To learn more, go to Upgrade Team Plans.Updated Credit Expiration Timeline
When you create an account, you receive a set of free credits. These free credits expire 90 days after you create your account.Personal Accounts Are Now Organizations
When you create an account, it is now automatically an organization. If you upgrade to a subscription plan, you keep the same organization. This means you get to keep your API keys, files, and settings. To learn more, go to Organizations & Members.Already on a subscription? Your Personal account and subscription organization remain separate. This ensures that files and data in your Personal organization are not shared with members of your subscription organization.April 2, 2026: Custom Prompts for Figure Descriptions
Custom Prompts for Figure Descriptions
The and ADE Parse Jobs APIs include a new optionalcustom_prompts parameter that lets you tell how to describe figures during parsing. This is useful when the default figure descriptions do not fit your use case, such as for domain-specific charts or images unique to your organization.Pass your prompt in the custom_prompts parameter when calling the ADE Parse or ADE Parse Jobs APIs, or using the Python and TypeScript libraries.The custom_prompts parameter is only supported when using .For more information, see Custom Prompts for Figure Descriptions.April 2, 2026: SSO Support for SAML 2.0 and OIDC
SSO Support for SAML 2.0 and OIDC
Enterprise plans now support single sign-on (SSO) via SAML 2.0 and OpenID Connect (OIDC). SSO allows your organization to manage access through your existing identity provider (IdP).To get started, see Single Sign-On (SSO).March 20, 2026: DPT-2 mini Updates
DPT-2 mini Updates
includes the following updates:- Improved table accuracy: Table parsing accuracy has been improved for simple tables.
- Visual element captions: now generates concise captions for image-based chunk types, including
figure,logo,card,attestation, andscan_code.
March 12, 2026: New Parsing Model Snapshots and Parse Password-Protected Files
New Parsing Model Snapshots
New snapshots of and are now available:- :
dpt-2-20260302 - :
dpt-2-mini-20260302
dpt-2-20260302 builds on previous versions with several improvements, including:- Table boundary detection: Tables that were previously split into multiple chunks are now correctly identified as a single table.
- Improved large table accuracy: Large tables are now parsed more accurately.
- Special characters returned as Unicode: Characters such as asterisks are now returned as their Unicode characters (for example,
*) rather than as spelled-out strings likeasterisk.
The table boundary detection and large table accuracy improvements are also included in
dpt-2-mini-20260302.How This Affects Your Results
If your code usesdpt-2-latest, dpt-2, dpt-2-mini-latest, or dpt-2-mini, it now points to these new snapshots and your parsing results may change.To receive the latest improvements automatically, continue using a -latest alias. To maintain consistent results over time, pin your code to a specific snapshot (for example, dpt-2-20251103). For more information, go to Why Model Versioning Matters.Parse Password-Protected Files
Accounts with Zero Data Retention (ZDR) enabled can now parse password-protected files. Pass the document’s password in thepassword parameter when calling the ADE Parse or ADE Parse Jobs APIs, or using the Python and TypeScript libraries.For more information, go to Parse Password-Protected Files.March 4, 2026: LandingLens and LandingEdge Documentation Has Moved
LandingLens and LandingEdge Documentation Has Moved
Documentation for LandingLens and LandingEdge has moved to landinglens.docs.landing.ai.Existing links to docs.landing.ai/landinglens and docs.landing.ai/landingedge will automatically redirect to the new site.February 26, 2026: Extraction Schema Validation Fix
Extraction Schema Validation Fix
The API now correctly validatesanyOf sub-schemas before processing begins. If a sub-schema within anyOf is missing both the type and anyOf keywords, the API returns a 400 error identifying the invalid path in the schema. Previously, this caused an unexpected extraction failure.For more information about extraction response statuses and errors, go to Troubleshoot Extraction.February 12, 2026: In Preview - Confidence Scores for Parsing
Confidence Scores
The parsed results now include confidence scores for text, marginalia, card, and table chunks, as well as table cells.Confidence scores measure the confidence level of parsed text in Markdown with respect to the actual text or visual data present in the document.Each score ranges from 0.0 (low confidence) to 1.0 (high confidence). Lower values indicate regions where the model was less certain about the output.The confidence score feature is in Preview. The numeric range and distribution may change as we continue to develop and improve the model.
Use Confidence Scores in the Playground
After parsing a document in the Playground, turn on the Confidence toggle (the toggle is only available when using ).In the Markdown tab, the confidence score displays next to the chunk type.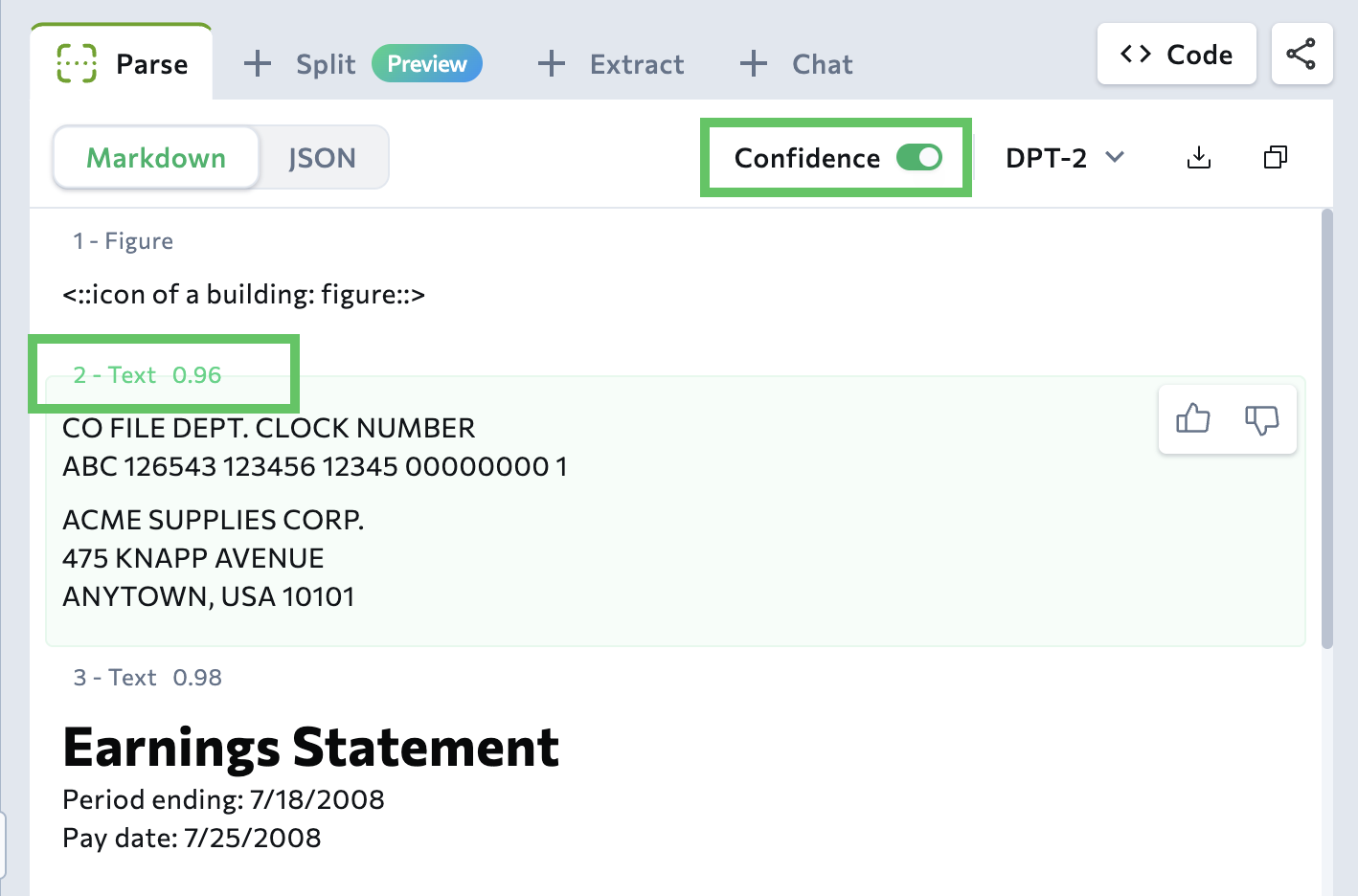
Review Low-Confidence Sections
Low-confidence sections (with scores of 0.95 or lower) are highlighted in yellow in the Playground. Highlighting low-confidence sections helps you quickly identify content that may need review.- Text, card, marginalia chunks: Specific text spans within a chunk are highlighted. A single chunk can contain multiple highlighted spans.
- Tables: Each cell has its own confidence score. If a cell has a low score, the entire cell is highlighted.
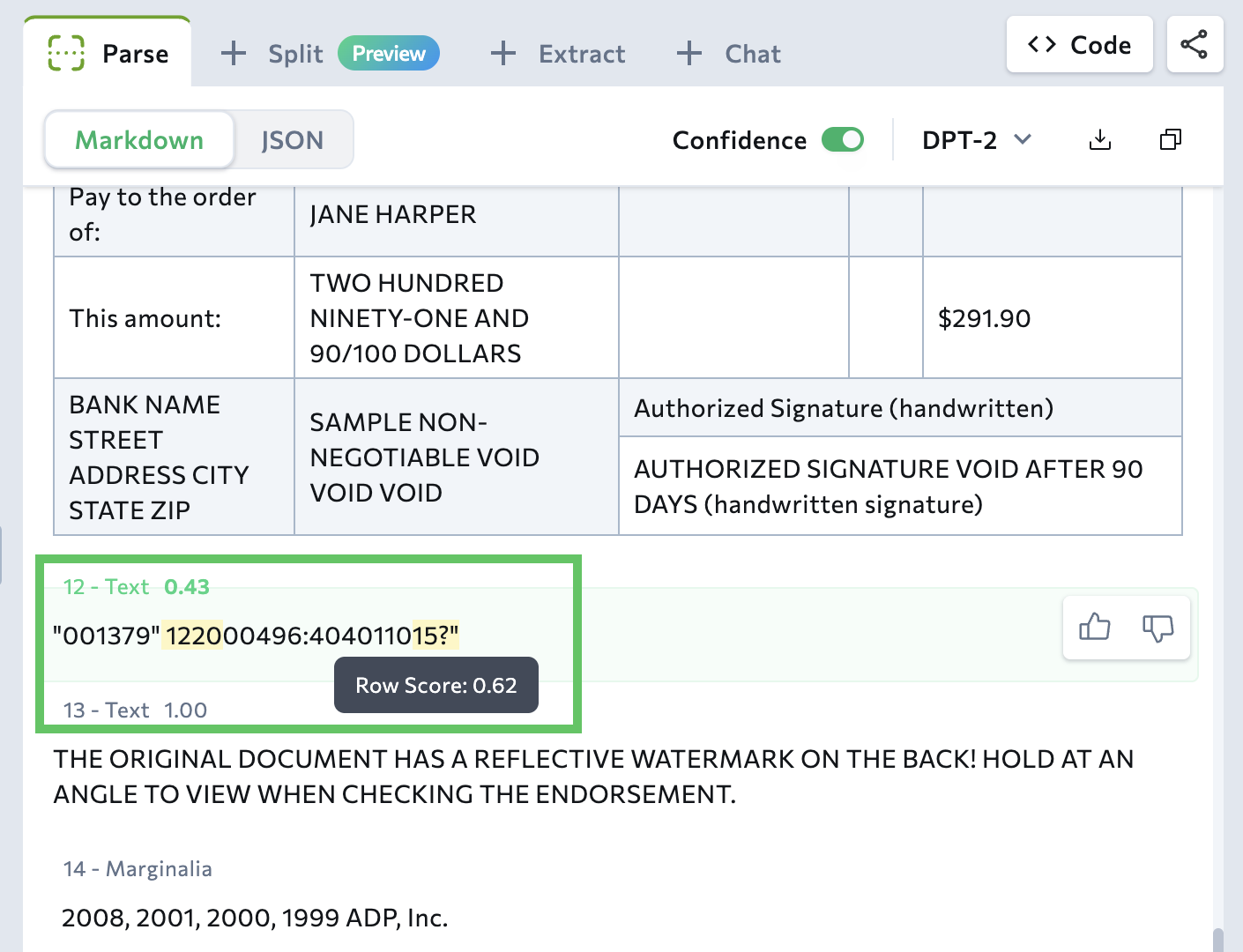
Why is 0.95 the threshold for low confidence scores?
The Playground highlights content with confidence scores of 0.95 or lower because this is the threshold used internally to evaluate parsing quality.This threshold works well for general review workflows, but your use case may require a different threshold. When using the API, you can implement custom logic to identify and route content based on confidence scores that match your specific requirements.Why don’t I see the confidence score for files I uploaded in the past?
The confidence score displays for documents parsed on February 12, 2026 or later. If you parsed a document before that date, the Playground does not re-process documents.If you want to see the newest results for a file that you’ve already parsed, re-upload it to the Playground.Use Confidence Scores in the API Response
Thegrounding object in the API response includes all the confidence information displayed in the Playground:- Confidence scores for each chunk and table cell
- For text chunks with low-confidence spans: the text, confidence score, and character positions (
start,end) for each span
DPT-1 Will Be Deprecated on March 31, 2026
will experience a technology change on February 17, 2026 that may affect parsing results, and will be fully deprecated on March 31, 2026.If you are using , update your code to use DPT-2. To learn more about DPT models, go to Document Pre-Trained Transformers (Parsing Models).
DPT-1 Underlying Technology Change: February 17, 2026
One of our underlying solution providers for is upgrading their technology on February 17, 2026. While will continue to function, table parsing behavior and results may change for some documents.DPT-1 Deprecation: March 31, 2026
Longer term, we plan to deprecate . After March 31, 2026, will no longer be supported and will be scheduled for shutdown.Impacted Users and Next Steps
Check the scenarios below to determine if you are impacted and what action to take. Complete any necessary migration before February 17, 2026.- Scenario 1: You Specify DPT-1 as the Model Parameter
- Scenario 2: You Use the Legacy API Endpoint
- Scenario 3: You Use the Legacy Python Library
Scenario 1: You Specify DPT-1 as the Model Parameter
You are in this scenario if:- You call the
/v1/ade/parseor/v1/ade/parse-jobsendpoint
- You set the
modelparameter todpt-1,dpt-1-latest, ordpt-1-20250615
model=dpt-2-latest or a specific snapshot.For example, run the command below to use the latest snapshot of .Scenario 2: You Use the Legacy API Endpoint
You are in this scenario if you call the legacy endpoint:v1/tools/agentic-document-analysis.What to do:-
Migrate to the
/v1/ade/parseendpoint. To learn how to use this endpoint, go to ADE Parse. -
When calling the endpoint, use
model=dpt-2-latestor a specific snapshot. For example, run the command below to use the latest snapshot of .
Scenario 3: You Use the Legacy Python Library
You are in this scenario if you use the legacyagentic-doc Python library.What to do:- Migrate to the library. To learn how to use this library, go to Python Library.
-
Update your code to use
model="dpt-2-latest"or a specific snapshot when calling theparse()function. For example, use this code to use the latest snapshot of .
February 5, 2026: Load Multiple Files at Once
When using the Playground, you can now load up to 10 files at once. After opening the Upload dialog box, navigate to and select multiple files or simply drag and drop the files.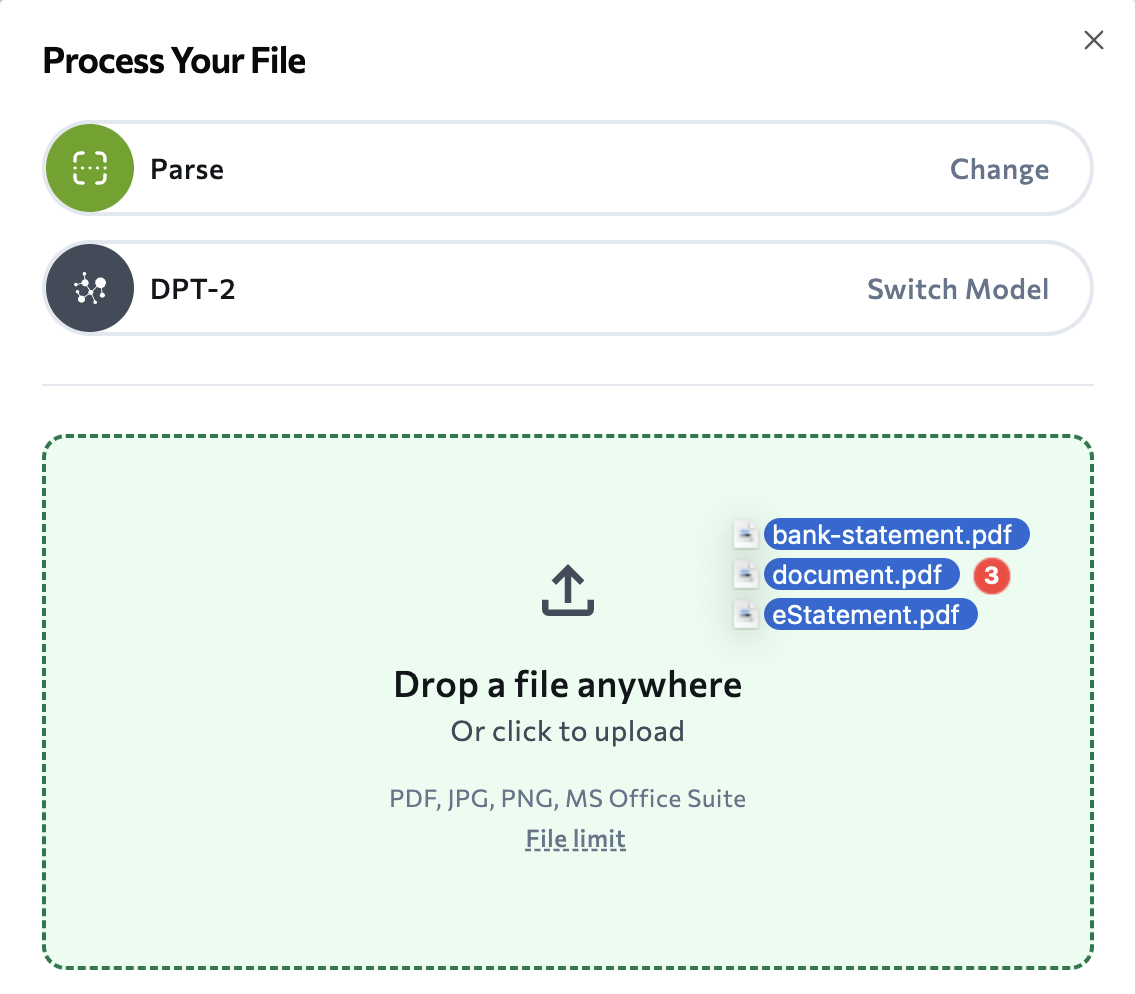
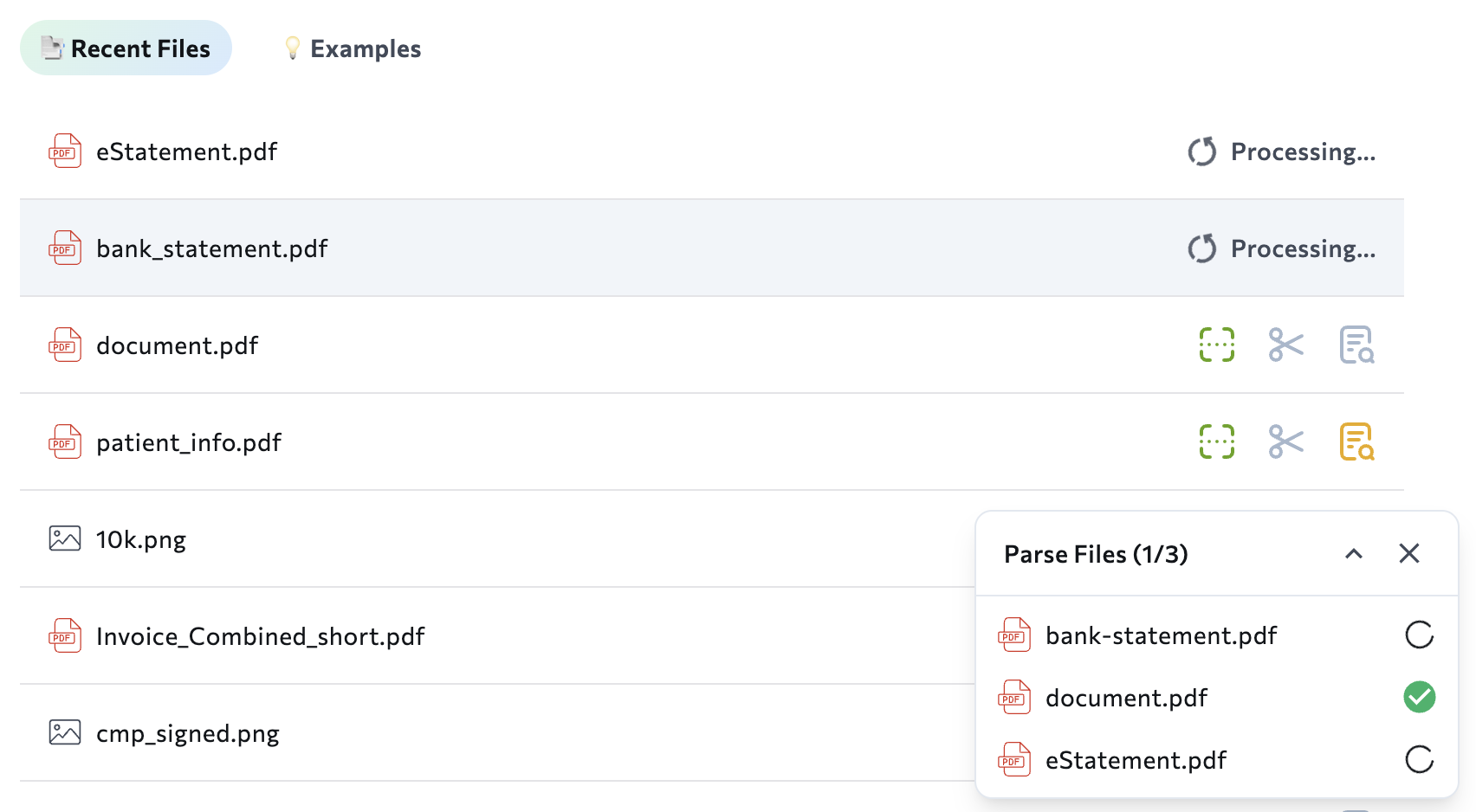
Parsing Status
After loading multiple files into the Playground, a floating dialog box appears in the bottom right corner, showing the parsing progress for each file. If a file fails to process, an error message displays in this area.Multiple File Upload Not Available with ZDR
When Zero Data Retention (ZDR) is enabled, only one file can be loaded at a time.January 30, 2026: Python and TypeScript Libraries Support Saving Responses to Local Directories
Python and TypeScript Libraries Support Saving Responses to Local Directories
The and libraries now support saving API responses directly to local directories as JSON files.The save parameter:- Creates the specified directory if it doesn’t exist
- Saves the response with the filename format:
{input_file}_{method}_output.json - Works across all three core functions: parse, split, and extract
Availability
- Python library: v1.4.0 (parameter:
save_to) - TypeScript library: v2.0.0 (parameter:
saveTo)
Example
These examples show how to save the API response when parsing.January 6, 2026: Table Cell Position Information in Parsing Results
Table Cell Position Information
When you parse documents with tables, the API response now includes row and column position information for each table cell in thegrounding object. This allows you to map parsed data back to specific cell locations in the original table.Each table cell in the grounding object now includes a position field with:row: Row position (zero-indexed)col: Column position (zero-indexed)rowspan: Number of rows the cell spanscolspan: Number of columns the cell spanschunk_id: Associated chunk identifier
- Precise cell mapping: You can now identify the exact row and column for each piece of data in your table
- Merged cell detection: The rowspan and colspan values indicate when cells are merged
- Easier data validation: You can verify that extracted data came from the expected cell location
December 16, 2025: Extraction Model Fallback Tracking & Parse Jobs 206 Status
This release includes a new metadata field for tracking extraction model fallbacks, improved HTTP status codes for parse jobs with partial results, improved spreadsheet parsing, and documentation updates to Parse Jobs endpoint names.
Fallback Model Version Field
The API response now includes ametadata.fallback_model_version field. This field shows which extraction model was actually used if the API falls back from your requested model.For more information about the response structure, go to JSON Response for Extraction.Parse Jobs: Partial Content Now Returns a 206 Status
When you retrieve parse job results with the ADE Get Parse Jobs API, the API now returns a 206 (Partial Content) HTTP status code if some pages failed during processing.Thefailed_pages array and failure_reason field that were already in the API response continue to provide details about which pages failed and why.For more information, go to Troubleshoot Parsing.Improved Title Detection in Spreadsheets
The API now better identifies titles in spreadsheets. When a spreadsheet has a title or text at the top, the API now returns:- The title as a separate text chunk
- The table as its own chunk
You Can Now Resubscribe and Cancel in Interface
If you want to resubscribe to or cancel a subscription plan, you can now do so directly in the interface. For full details, go to Pricing & Billing.Updated API Endpoint Names
We’ve updated the names of two Parse Jobs API endpoints:- “List Async Jobs” is now “ADE List Parse Jobs”
- “Get Async Job Status” is now “ADE Get Parse Jobs”
December 4, 2025: Document Splitting Is Now in Preview
Split Documents with the New Split API (Preview)
We’re releasing a Preview of the API, which classifies and separates a parsed document into multiple sub-documents based on Split Rules you define. This is useful when you receive batched documents containing multiple document types or multiple instances of the same document type.For example, a financial institution processing KYC documentation might receive a single PDF containing bank statements, utility bills, and identification documents for a customer. The API can automatically classify and separate each document type, enabling downstream processing systems to route each document appropriately.Get the full details in Split. is in Preview. This feature is still in development and may not return accurate results. Do not use this feature in production environments.
How It Works
- Parse your document using the API to generate Markdown output
- Define Split Rules that describe the document types or sections you want to identify
- Call the API with the parsed Markdown and your Split Rules
- The API returns each classified sub-document with its full Markdown content
When to Use Split
Use the API when you need to:- Separate batched documents containing multiple document types (invoices, receipts, contracts)
- Split documents with repeated sections by unique identifiers (multiple pay stubs by date)
- Organize multi-section documents into logical parts (academic articles with body, references, supplemental materials)
- Route different document types to appropriate downstream systems
How to Use Split
The API is available through multiple interfaces:- Playground: Interactively create and test Split Rules
- API: Integrate directly into your applications
- Python Library: Integrate into Python-based application with our Python library
- TypeScript Library: Integrate into TypeScript-based application with our TypeScript library
December 4, 2025: Revamped Playground
Revamped Playground
We’ve launched a complete redesign to our Playground! The updated Playground now guides you through each step of the document processing process: Parsing, Splitting, and Extraction. Simply click a tile to get started!You can now see all the files you’ve processed on your Playground homepage, including which tools you’ve run on each file (parse, extract, split).We’ve also made it easier to get help with by adding Product Update and Resources panels.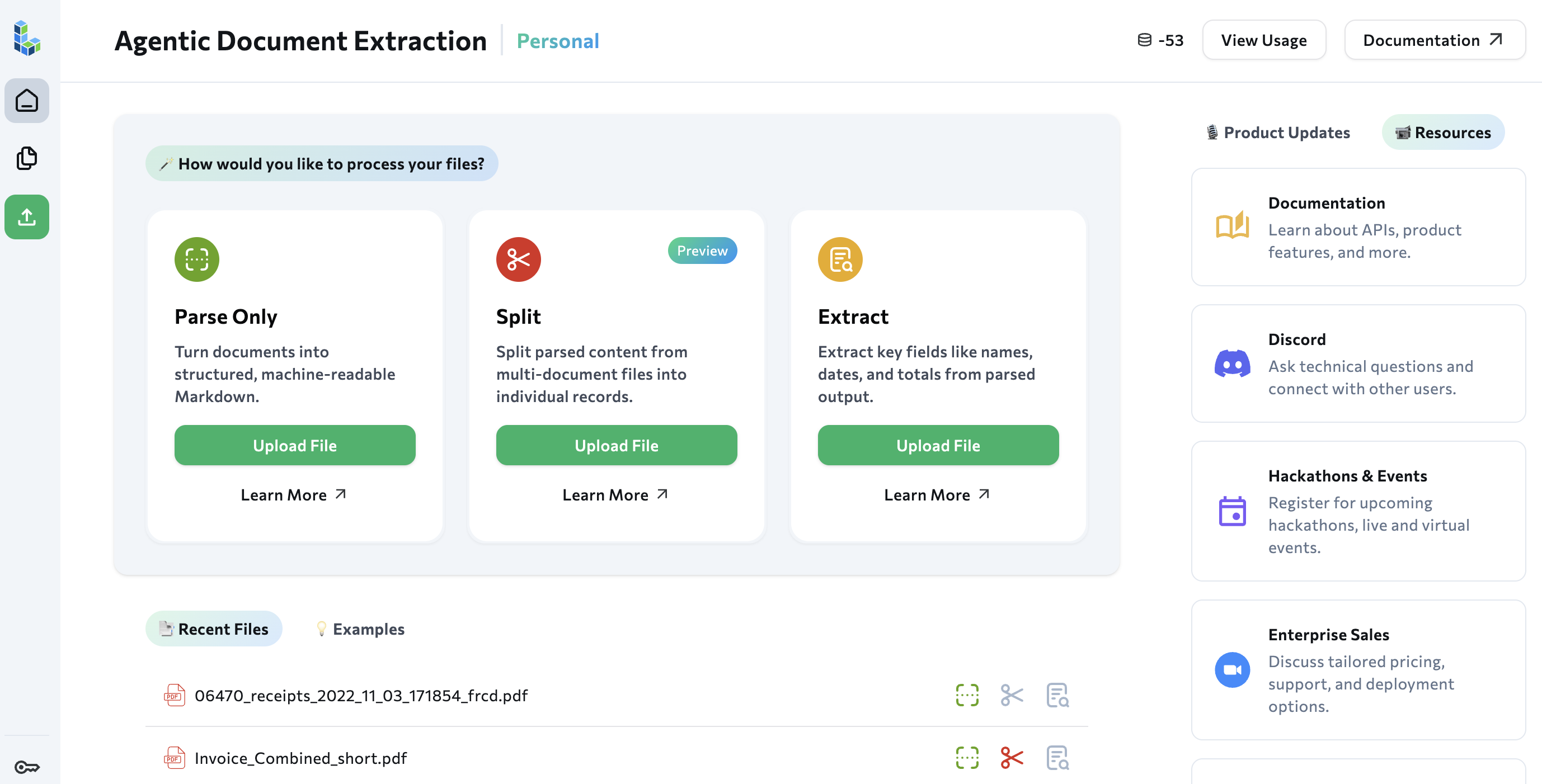
November 27, 2025: Updates to Parse Jobs
The Parse Jobs API Supports up to 6,000-Page Documents
The ADE Parse Jobs API now supports documents up to 6,000 pages long. Previously, the limit was 1,000 pages.For more information, go to Rate Limits for ADE Parse Jobs.Improved Support for Partial Content with the Parse Jobs API
We’ve improved how the ADE Parse Jobs API handles partially parsed documents.Previously, if any pages failed to process, the job would fail with statusfailed.Now, the API processes all pages in the document. If some pages fail, the job completes with status completed, and the successfully processed pages are returned in the results.The failed_pages array in the metadata lists which pages failed, and the failure_reason field provides details about the failures.For more information, go to Troubleshoot Parsing.The Parse Jobs API Supports Additional Storage Providers for ZDR
When calling the ADE Parse Jobs API with zero data retention (ZDR) enabled, you must include theoutput_save_url parameter. This parameter specifies the URL where parsed results are saved, ensuring that does not store the document content.We have now tested and confirmed support for Amazon S3, Azure Blob Storage, and Google Cloud Storage. Other storage providers that support PUT or CREATE operations via public or presigned URLs may also work.For detailed information, go to Requirements for ZDR.November 17, 2025: Credit Rounding Updated
Credit Rounding Updated
Credit usage for the API and is now rounded up to the nearest tenth decimal place instead of the nearest whole credit.For example, if a calculation results in 1.67 credits, the cost is now rounded up to 1.7 credits (previously would have been rounded up to 2 credits).For more information, go to Pricing & Billing.November 12, 2025: DPT-2 mini Launch
DPT-2 mini Preview
We’ve released a preview of , a lightweight parsing model optimized for simple, digitally native documents. consumes fewer credits than other parsing models, making it a cost-effective option for straightforward document processing. is in Preview. This model is still in development and may not return accurate results. Do not use this model in production environments.
Credit Consumption
consumes fewer credits than other parsing models. If ZDR is enabled, credit consumption increases.For pricing details, go to Pricing & Billing.November 10, 2025: DPT-2 Is Now Generally Available, Spreadsheet Support, and Credit Rounding
DPT-2 Is Now Generally Available
, the latest series of parsing models for , is now generally available (GA). As part of going GA, we’re releasing this new snapshot:dpt-2-20251103. This updated version offers improvements to table parsing, figure captioning, and chunk detection.For more information about parsing models, go to Document Pre-Trained Transformers (Parsing Models).How This Affects Your API Calls
The new snapshotdpt-2-20251103 is now the default model. If you call the ADE Parse or ADE Parse Jobs API without specifying a model parameter (or if you use dpt-2-latest), your API calls will automatically use this latest snapshot.Your parsing results may change with this update due to improvements in table parsing, figure captioning, and chunk detection.Choose Your Approach
You can choose between two approaches when setting themodel parameter:Get automatic improvements:- Omit the
modelparameter, or set it todpt-2-latest - Your API calls will automatically use the latest snapshot
- You’ll receive parsing improvements as new snapshots are released
- Parsing results may change when new versions are released
- Set the
modelparameter to a specific snapshot (likedpt-2-20251103) - Your parsing results will remain consistent over time
- You won’t automatically receive improvements from new snapshots
Spreadsheet Support
can now parse the following file types:- CSV (comma-separated values)
- XLSX (Microsoft Excel)
Credits Are Now Rounded Up
Credit usage for the API is now rounded up to the nearest whole credit. For more information, go to Pricing & Billing.October 27, 2025: New File Types, Increased Page Limits & EU Subscriptions
Support for Text Documents & Presentations
can now parse the following file types:- DOC (Word)
- DOCX (Word)
- PPT (PowerPoint)
- PPTX (PowerPoint)
- ODT (OpenDocument Text)
Document Length Limit Increased to 100 Pages
now supports documents with up to 100 pages in both the Playground and via the API.Need to parse longer documents? Use the ADE Parse Jobs API to parse documents that are up to 1,000 pages or 1 GB.For more information, go to Rate Limits.Subscriptions Now Available for EU Users
The EU-hosted version of now offers monthly subscription plans. To see the plans and upgrade, go to the EU Plans page.The credit-based monthly subscription plans are designed to deliver more value and features to your team.All EU users start on our pay-as-you-go plan that comes with free credits to help you get started! Once you’re ready for production, upgrade to a monthly subscription plan to get access to these features:- More credits per dollar
- One-click Zero Data Retention (ZDR)
- Organization management
- Role-based access control (RBAC)
- API key management
October 10, 2025: New APIs for Parsing Large Documents
New APIs for Parsing Large Documents
We have released new APIs that allow you to create parsing jobs. These APIs allow you to process large documents without blocking other operations, improving performance and user experience.To learn more about this workflow, go to Parse Large Files (Parse Jobs).API Reference
To learn more, go to the reference pages for new APIs:September 30, 2025: DPT Models
Document Pre-Trained Transformers: You Can Now Pick a Parsing Model
In this release, we’re previewing a concept called (DPT). A DPT is the model that powers the parsing capabilities of the ADE Parsing APIs. The DPT identifies document layouts and chunks, then generates descriptive explanations (captions) for those chunks.The API initially launched with a single DPT model called . Because there was only one DPT, it was not surfaced to users.We are now introducing , which offers:- Improved performance for complex tables
- Support for new chunk types (including barcodes and ID cards)
- More precise captioning for figures
ADE Parse and ADE Extract Are Now Generally Available
The and APIs are now Generally Available (GA). We recommend using these endpoints moving forward.New Python Library
We’ve launched a new Python library to support extending the APIs: the library.Key benefits:- Support for the and APIs.
- Support for setting the .
- The library is automatically generated from our API specification, ensuring you have access to the latest endpoints and parameters.
- The library is lightweight, which makes it suitable for resource-constrained environments like AWS Lambda functions.
agentic-doc Library Transitioned to Legacy Status
The agentic-doc Python library has been transitioned to legacy status.Migrate to the new library, which is now the recommended Python library for .The tools/agentic-document-analysis Endpoint Is Now Legacy
This endpoint has been transitioned to legacy status:https://api.va.landing.ai/v1/tools/agentic-document-analysis.Migrate to the new and APIs.September 12, 2025: Separate APIs for Parsing & Extraction
Separate APIs for Parsing & Extraction
In our original launch of , the field extraction function was part of the parsing function; every time you wanted to run extraction, you had to run parsing, even if you had already parsed the document.We are now introducing a Preview of two new endpoints that separate these functions: and . These APIs allow you to decouple parsing and extraction workflows for greater flexibility.You can now parse the document once with the API, and then use the API to run field extraction on that output multiple times. This is helpful if you want to experiment with different extraction schemas or you have multiple extraction tasks.To get detailed information about how to use these new APIs, go to Separate APIs: Parse & Extract.August 20, 2025: Launch - Subscriptions & New Features
Monthly Subscriptions
We’re excited to announce a major update to Agentic Document Extraction! We’ve just launched credit-based monthly subscription plans designed to deliver more value and features to your team.Learn more about available plans in Pricing.All users start on our pay-as-you-go plan that comes with free credits to help you get started! Once you’re ready for production, upgrade to a monthly subscription plan to get access to these new features:- More credits per dollar
- One-click Zero Data Retention (ZDR)
- Organization management
- Role-based access control (RBAC)
- API key management
One-Click Zero Data Retention (ZDR)
Users on subscription and Enterprise plans can turn on zero data retention (ZDR) directly in the user interface! This ensures that your documents are processed in-memory and are never stored at rest on LandingAI systems or by our sub-processors.To learn more, go to Zero Data Retention (ZDR) Option Overview.Organization Management
Upgrading to a subscription or Enterprise plan automatically creates an organization. An organization contains all of the credits, members, API keys, and settings for the plan.To learn more, go to Organizations & Members.Member Management: Role-Based Access Control (RBAC)
Users on subscription and Enterprise plans can invite multiple users to their organization. These plans offer granular member controls, including the ability to:- invite members
- assign roles to members that determine what functions they can perform
- change member roles
- revoke invitations
- remove members
API Key Management
Users on subscription and Enterprise plans can create multiple API keys for their organization. These plans offer granular API key controls, including the ability to:- create API keys
- revoke API keys
July 17, 2025: European Union Availability
Agentic Document Extraction Now Available in Europe
Agentic Document Extraction is now available in Europe. To learn more, go to European Union (EU).Agentic Document Extraction in the EU provides:- Data residency: All data is stored and processed within the EU
- GDPR compliance: Coming soon; learn more at our Security and Data page
- Regional performance: Reduced latency for European users
May 14, 2025
Improved Accuracy
now delivers higher accuracy when extracting data from complex tables and multi-column layouts.Increased Processing Speed
is now significantly faster than before, so you can process thousands of pages per minute.Process Longer Pages
We’ve increased our page limits, so that you can process longer documents.For more information, go to Rate Limits.Zero Data Retention
Users on the Custom plan can enable a zero data retention policy, ensuring all data is deleted immediately after processing—supporting strict privacy and compliance requirements.For more information, contact us.Consolidated Chunk Types
We consolidated these chunk types intopage_header:page_headerpage_footerpage_number
form:formkey_value